Built for High-Stakes Data Teams,
Not Marketing Slides
Every feature comes from real investigative work—and adapts seamlessly to researchers, analysts, and anyone who needs high-speed answers from messy data.
Core Capabilities
Ingest Anything
From chaos to clarity in seconds
Universal File Processing
"If it's a file, we can process it"
- 1,000+ supported formats out of the box
- Automatic OCR for image files and scanned PDFs
- Structured data types: CSV, JSON, parquet, ORC, and more
- Metadata captured for forensics
Enterprise Data Pipeline
"Production-grade processing architecture"
- Battle-tested orchestration engine
- Automatic retry and error handling
- Scales from laptop to cluster
- Real-time processing status
- Customized ETL without equal
See What's Inside
Documents as they were meant to be seen
Full Document Intelligence
"Open a document. See everything in it."
- Images embedded in PDFs and Word documents appear inline
- Image files open directly in the viewer
- Scanned documents: OCR text alongside the original visual
- Every image reference in text is clickable — full size on demand
In-Document Navigation
"Search doesn't stop at the document — it continues inside it."
- Search highlights guide you to every match
- Previous/next navigation — no manual scrolling
- Works in both Search and Discover views
- One-click phrase search hint for multi-word queries
Discover Mode
Start with what's there, not what you already know
Entity-Led Exploration
"When you don't yet know what to search for."
- Browse entities by type: people, organizations, emails, addresses, and more
- Filter by date range across your document set
- Narrow by file type or collection
- Typeahead entity search — find the right filter instantly
Straight Into the Document
"Every result opens directly — no context switching."
- Inline document viewer — read without leaving the results
- Filters auto-collapse after search — results take center stage
- Active filters preserved across searches
- Mobile-responsive — full functionality on any device
Discover Mode — 728 results across 3 active filters
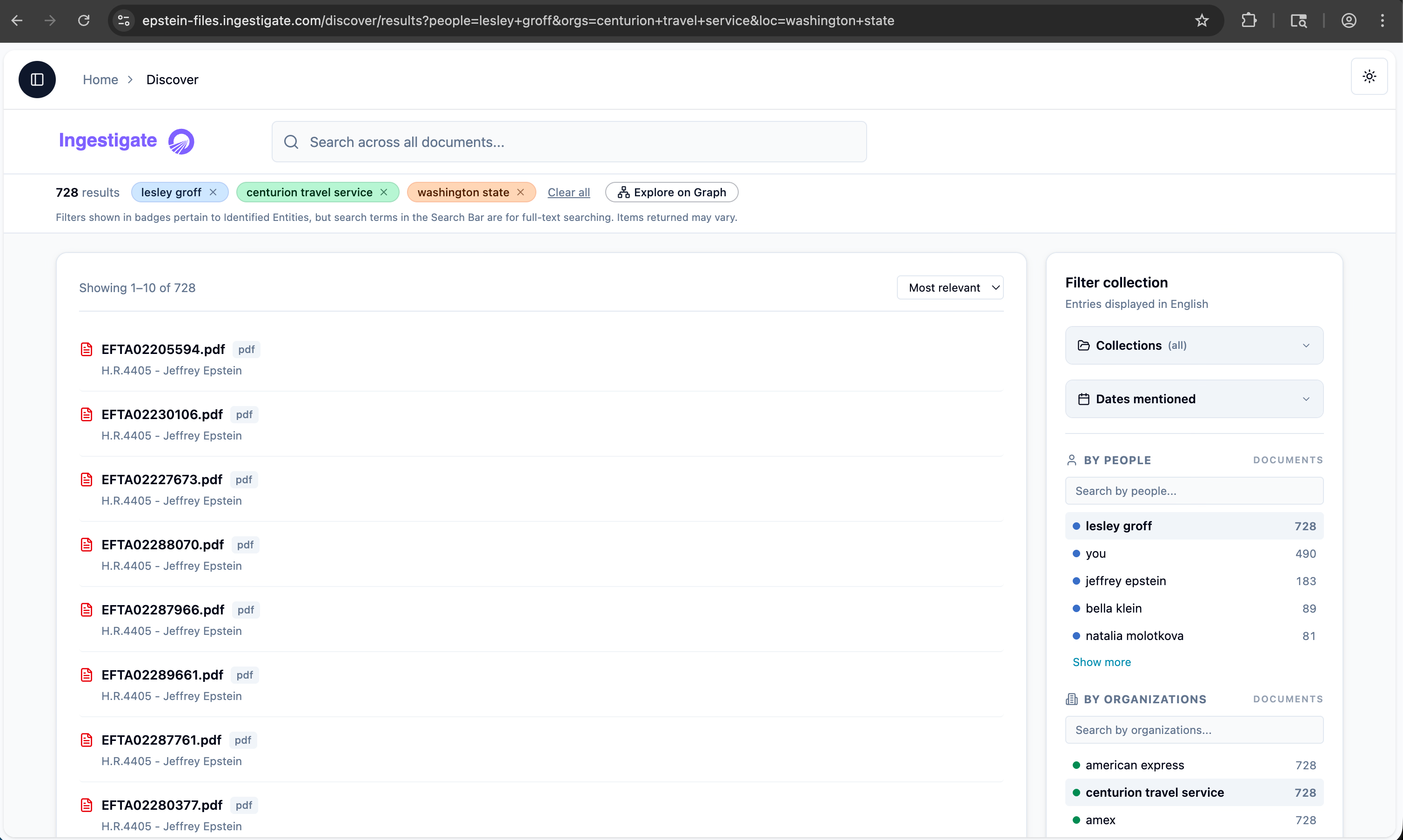
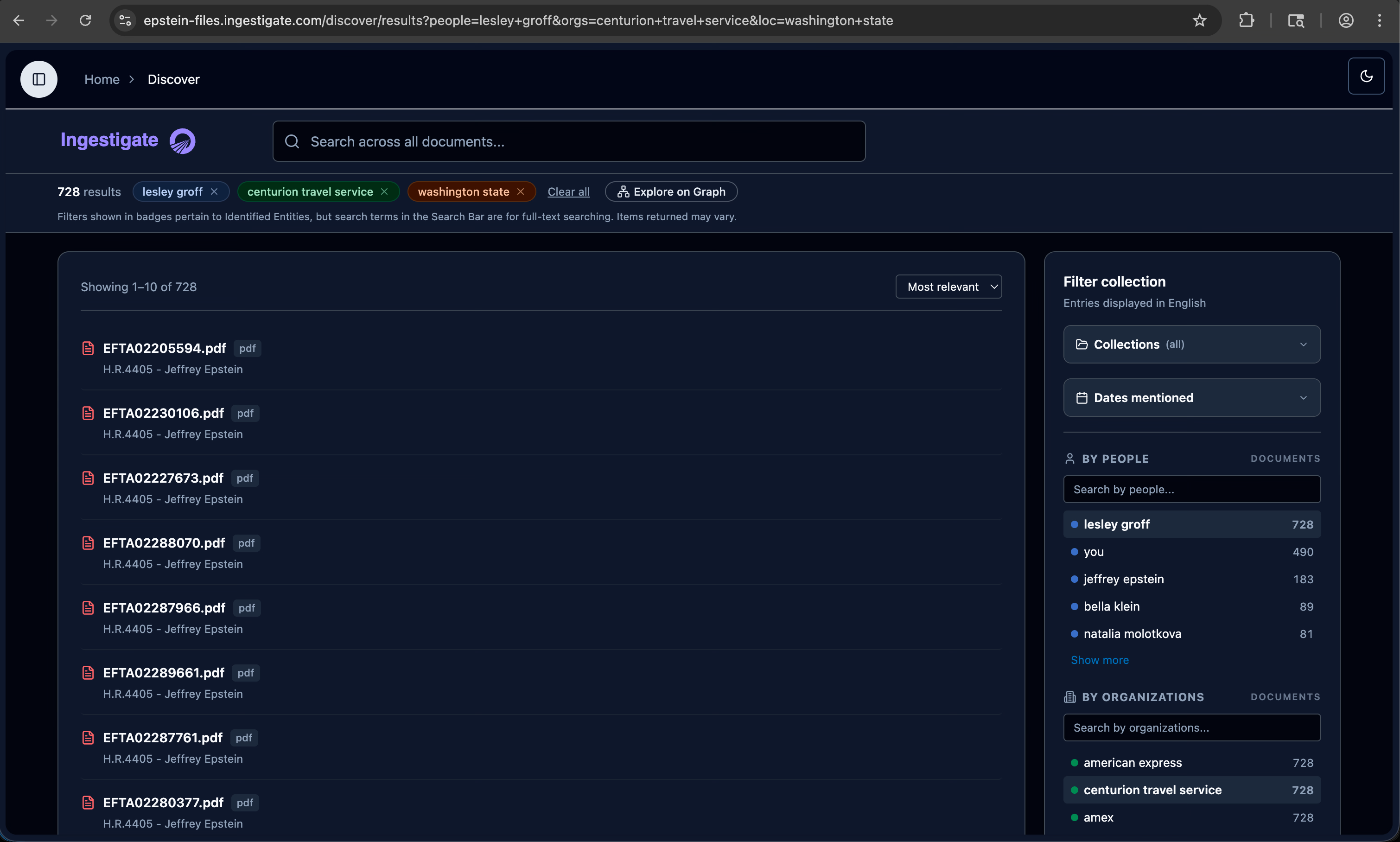
Three active filters — person, organization, location — narrowing 728 results. Entity facet panel shows document counts per name. One click opens any result directly in the document viewer.
Search Everything | Owners Control Access
Cross-organization visibility with owner-controlled access
Intelligent Search
"Find needles in petabyte haystacks"
- 0.2ms search response - faster than you can type
- Include/exclude terms with proximity search
- Search across investigations (with visibility controls)
- Real-time results as you type
Owner-Controlled Access
"Cross-org visibility, owner-controlled"
- See basic info for investigations in your organization
- View document names and owner info when restricted
- Owner-controlled access decisions
- Ask owner to be added to the team
- 3ms Investigation authorization (not per-row!)
- Policy Decisions are monitored and auditable
See the Network
Automatic entity extraction and relationship intelligence — with evidence behind every connection
Automatic Entity Recognition
"Find who, what, and where—automatically"
- Identify people, organizations, and locations
- Extract emails, phone numbers, crypto addresses
- Detect usernames and handles across platforms
- Process documents automatically during ingestion
- Named entity recognition (NER) — purpose-built for extraction, not a general-purpose language model
Relationship Intelligence
"See patterns you'd otherwise miss"
- Click any connection to see the source documents behind it
- Find paths between entities automatically
- Large graphs auto-cluster — drill in on what matters
- Document co-occurrence edges visually distinct from entity edges
- Match entities across your investigations
Runs entirely on your infrastructure
Entity recognition runs entirely within your deployment. No document content is sent to an external service. No API calls to third-party AI providers. Every extraction happens on your infrastructure — which matters for law firms with client confidentiality obligations, government agencies with data handling policies, and any organization under data residency requirements.
Graph Explorer — 176 nodes, 300 edges
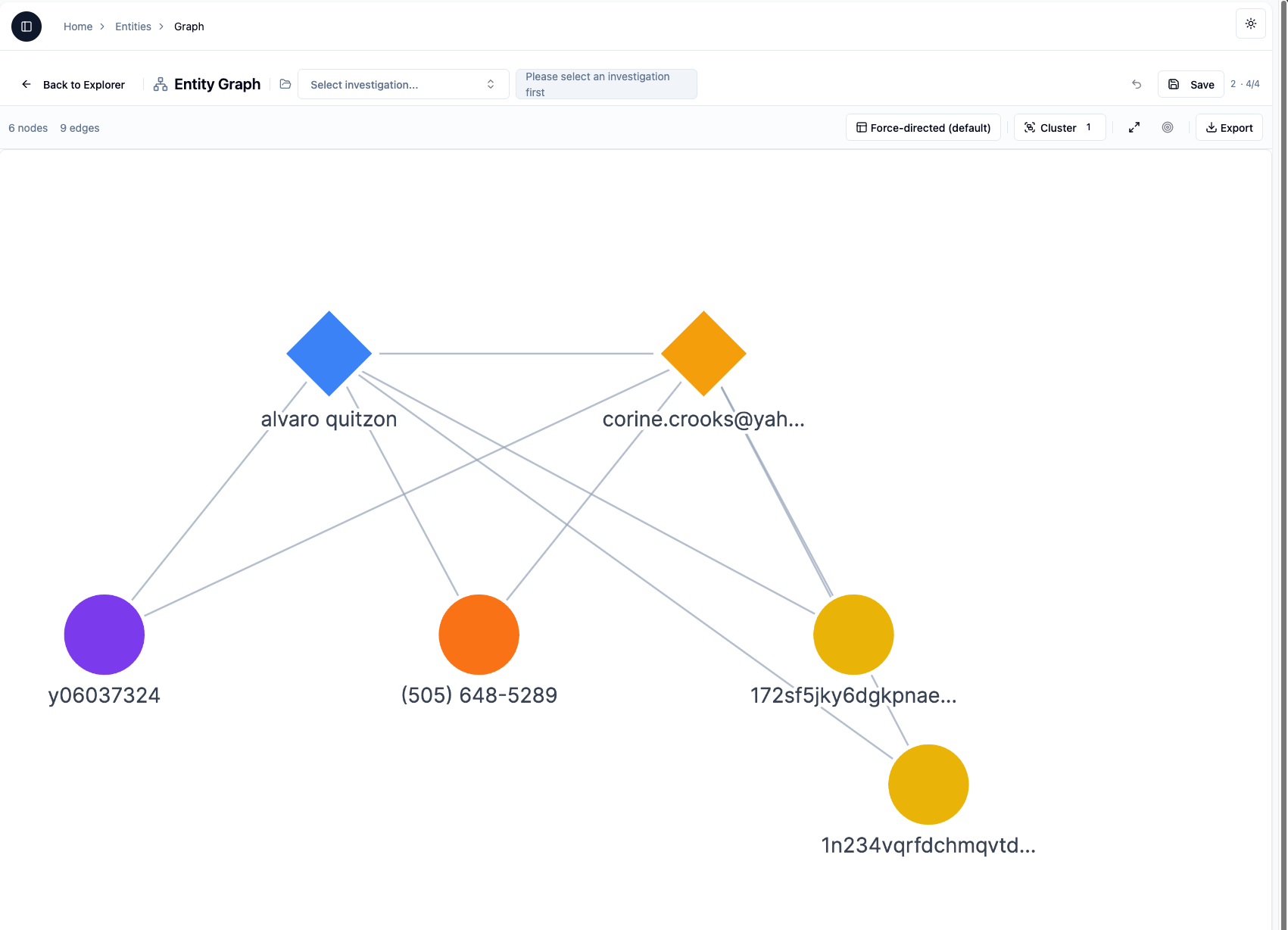
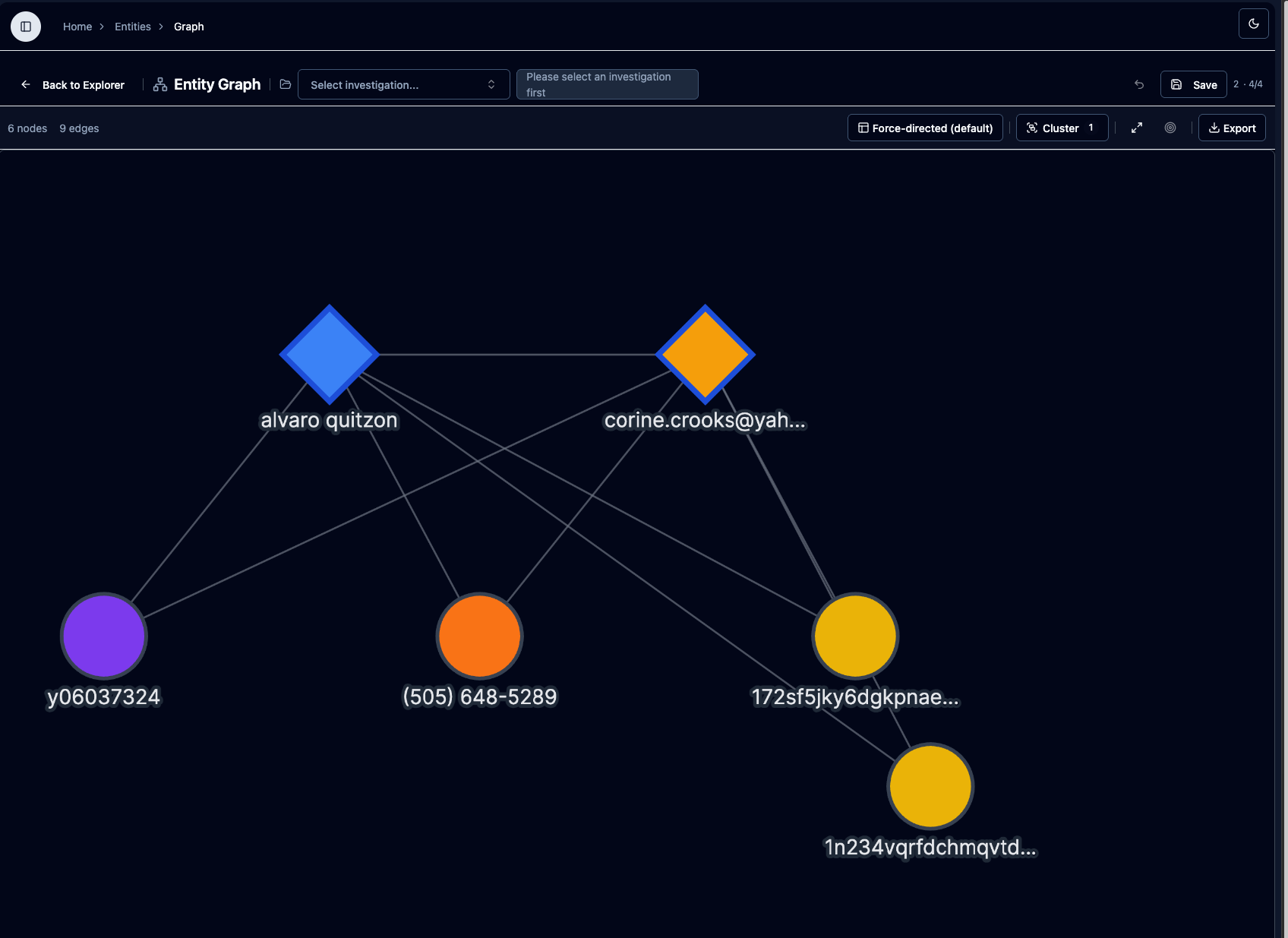
Real investigation data. Clusters auto-form on dense graphs — click any cluster to expand. Click any edge to see the documents behind the connection.
API-First Architecture
Your data, your tools
- Unlimited API calls (yes, really)
- Time-limited bearer tokens (Security by design)
- Comprehensive REST endpoints
- Python and JavaScript SDKs
- Webhook notifications
- Rate limiting for security and protection
Technical Specifications
- • Enterprise-grade policy-based auth framework
- • Enterprise-grade auth and IAM protocols
- • End-to-end encryption
- • On-premise deployment option
- • Complete audit logging
- • RBAC with organization isolation
Beyond Traditional Search
Search Inside Excel Columns. Query Parquet Files. No Exports Required.
Stop the painful export-import workflow. Ingestigate searches structured data directly— from messy spreadsheets to enterprise data dumps.
Product Roadmap
- ▸ Named Entity Recognition (NER)
- ▸ Automatic entity relationship mapping
- ▸ See What's Inside — full document viewer with images
- ▸ Discover mode — entity-faceted exploration
- ▸ Evidence-backed graph connections
- ▸ Export search results for reporting
- ▸ Concordance/Relativity load file export
- ▸ Enhanced collaboration tools
- ▸ Advanced filtering and tagging
- ▸ Deeper local AI / LLM integration — entity extraction already runs on-premise, expanding to classification and summarization
- ▸ Agent-driven investigation — OpenClaw skills already enable autonomous upload-to-conclusion workflows via API
Timeline subject to change based on user feedback and priorities
See These Features in Action
Watch a full investigation walkthrough on synthetic case data — no slides, just the platform working through a real investigation flow.

Ready to Transform Your Data Operations?
See the difference real-world investigative experience makes for every team that depends on messy data.
Available in the United States